Y-DNA Haplogroup R2
This Y-DNA haplogroup shares a common ancestor with Y‑DNA haplogroup R1 (R‑M173). While R1a and R1b haplogroups are often associated with the Indo-European languages, the original linguistic affinity of the R2 descendant haplogroups R2a and R2b remains unknown. There are not many studies focusing on deeper subclades of Y‑DNA haplogroup R2 (R-M479) and research tends to focus on the widespread subclades of haplogroup R1.
Ancient DNA samples carrying pure Y-DNA haplogroups R1* and R2* haven't been discovered yet. The oldest detected sample of R* related to both R1 and R2 is the 22000 BC Mal'ta Boy (MA1), who lived near the Lake Baikal and in archaeogenetics he represents the population of the Ancient North Eurasians (ANE).
The Y-DNA haplogroup R2 is mainly represented by its R2a (R2‑M124; R‑M124; R‑Y3399; R‑P249; R‑L266) subclade detected in 865 samples worldwide, while the R2b (R‑FGC50368; R‑SK2164; R2b‑FGC21706) subclade was seldom tested for and it was detected in only 13 samples worldwide.
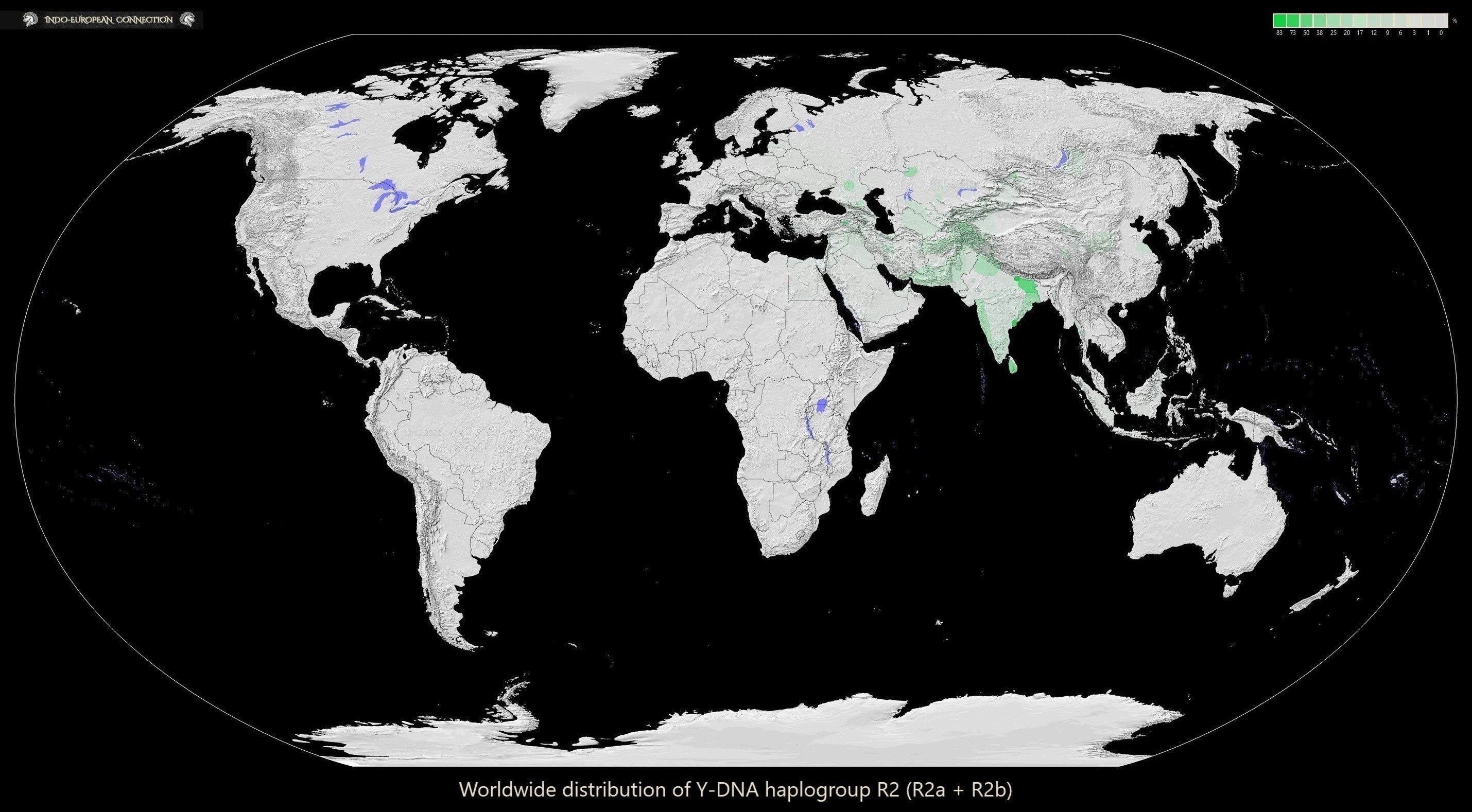
In Europe the Y-DNA haplogroup R2 is represented solely by the subclades of R2a (R‑M124) and peaks at 2% in Latvia, 1% in Lithuania, 1% in Belarus, 1% in Masovian Voivodeship of Poland, 1% in Slovakia, 1% in Ukraine, 1% in Moldova, 1% in Hungary and 1% in Switzerland. It does not appear at all in Romania, Serbia, Bulgaria, Scandinavia, Finland, Estonia, Western Poland, Germany, Austria, Ireland, Netherlands, Belgium, France, Spain and Portugal.
After collecting data from all genetic studies that detected (or didn't) the Y-DNA haplogroup R2a or R2b in many different populations and making a highly detailed heatmap with my own hands...
I present you the first ever map of worldwide distribution of Y-DNA haplogroup R2:
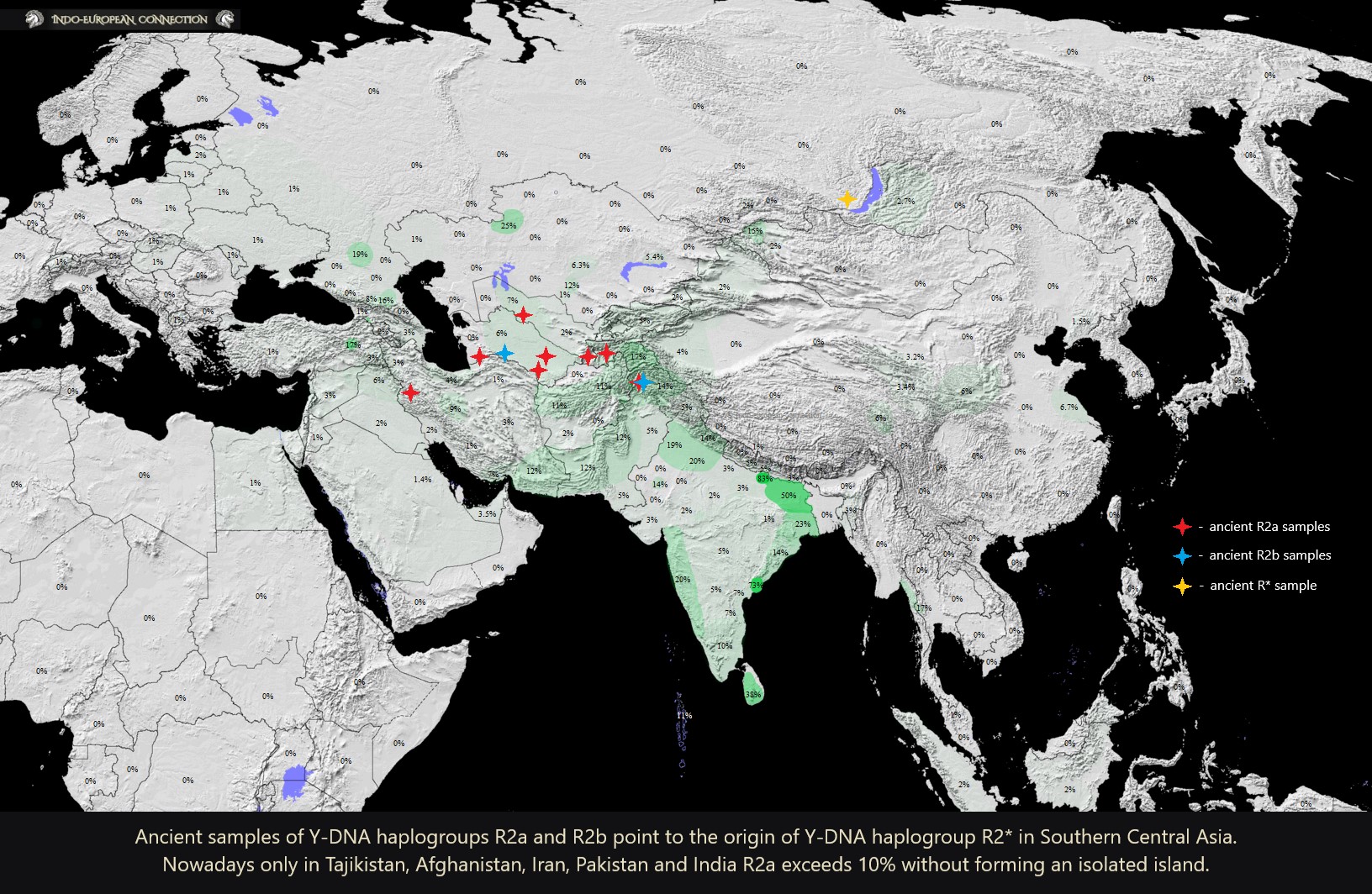
R2a in Ancient Samples
- 8241 BC - Ganj Dareh, Iran - Y‑DNA R2a (R‑Y3399), mtDNA unknown (sample I1949)
- 8000 BC - Ganj Dareh, Iran - Y‑DNA R2a (R‑Y3399), mtDNA J1c10 (sample I1945)
- 3500 BC - Geoksyur, Turkmenistan - Y‑DNA R2a (R‑Y8766), mtDNA J1d6 (sample I8526)
- 2196 BC - Gonur, Turkmenistan - Y‑DNA R2a (R‑Y3399), mtDNA R2 (sample I4087)
- 1971 BC - Sappali Tepe, Surxondaryo, Uzbekistan - Y‑DNA R2a-Y3370, mtDNA K1a (sample I7492)
- 1613 BC - Bustan (Boʻston), Uzbekistan - Y‑DNA R2a3a2, mtDNA HV2a2 (sample I11520)
- 1600 BC - Sumbar, Turkmenistan - Y‑DNA R2a-FGC13203 (from R2a‑Y3370), mtDNA W3b (sample I6675)
- 1207 BC - Katelai (Swat), Pakistan - Y‑DNA R2a3a2b2c, mtDNA U7b (sample I12147)
- 400 BC - Saidu Sharif (Swat), Pakistan - Y‑DNA R2a3a2b, mtDNA U2b2 (sample I7722)
- 356 BC - Aligrama (Swat), Pakistan - Y‑DNA R2a3a2b2b1, mtDNA HV6 (sample I8245)
- 166 BC - Ksirov (Danghara Plain), Tajikistan - Y‑DNA R2a (R‑Y3399), mtDNA U2e1e (sample I12292; Kushan)
- 670 AD - Roopkund, Uttarakhand, Northern India - Y‑DNA R2a3a2b2c, mtDNA HV14 (sample I3352)
The earliest sample containing Y-DNA R2a known to modern archaeogenetics is a man from Ganj Dareh, Iran. This ancient site belongs to the Neolithic Fertile Cresent region, which also contained sites such as Göbekli Tepe, Çatalhöyük, Chogha Golan, Chogha Bonut, Chogha Mish, Abu Hureyra and Jericho. A woman from Ganj Dareh (sample GD13a) shows genetic affinity with Baloch and Brahui from Pakistan and Makrani from Gujarat, India (Baloch mercenaries). R2a carrying male (sample I1945) from Ganj Dareh also carried the descendant haplogroup of mtDNA J1c, which nowadays appears only in Europe and North America, this points to a common origin of his ancestors in a population related to the Ancient North Eurasians.
Other males from the 3500 BC Geoksyur site in Turkmenistan carried the following Y-DNA haplogroups: P1 (or CT), 3x J‑ZS6592 (J1a2a1b1a), J‑ZS4428 (from J1a2a1b), J‑PF4993 (from J2a1a1a1a), Q-L56 (Q-M346; Q1a3). Just like the mtDNA haplogroup J1c, the Y-DNA haplogroup Q1a3 is nowadays widespread mostly among Native Americans, which points to the common ANE origin of Y-DNA P1, R2a and Q1a3 found at the Central Asian site of Geoksyur. This observation might also explain why in the 2021 Zhang et al. study the Tarim Mummies were modeled as 100% isolate but their genes were also found not only in the Neolithic Central Asian Geoksyur, Namazga and Sarazm individuals but also in the Botai, Okunevo, Dzungaria, Chemurchek, Bronze Age Baikal and Bronze Age Kumsay in Kazakhstan. They all shared a high level of Ancient North Eurasian (ANE) ancestry.
Nevertheless, the samples from Geoksyur, Namazga, Parkhai and Sarazm were still much closer (but not uniform) to Yamna Samara and Afanasievo Culture than to Tarim Mummies and Mal'ta Boy. The only samples from Central Asia shifted towards ANE the most were those from Bronze Age Aigyrzhal, Kyrgyzstan (circa 2100 BC) and resembled the ones from Early Bronze Age Dzungaria. The downward shift of Geoksyur and Namazga from Yamna Samara was mostly due to its high genetic input from Iran Neolithic and Anatolia Neolithic, in evidence from that earliest 8211 BC Ganj Dareh sample and lots of Y‑DNA J1a and J2a in Southern Central Asia. That is why the pre-Steppe carries of Y‑DNA R2a in Central Asia can be modeled in aDNA as 10% ANE, 20% Anatolia Neolithic and 70% Iran Neolithic (that is 90% of Fertile Crescent or Zagrosian DNA). The Elamites might be genetically closest to people from the Neolithic Central Asia but this requires some further examination.
The phenetic analysis of Tarim Mummies from Bronze Age Qäwrighul (1800 BC) also pointed to their uniqueness and to their slight affinity towards people from the Oxus Civilization (BMAC) and Sappali Tepe. However, no Y‑DNA R2a has ever been detected in any of the Tarim Mummies from the Xiaohe Cemetery (2100 BC - 1700 BC) and instead they carried mainly the descendants of Y‑DNA haplogroup R1*: 2x R1b‑PH155 (R1b2), 7x R1a1a, 1x R1‑M173. The remaining not deeply classified Y‑DNA haplogroups from Xiaohe were: F‑M89 (East, South and Central Asian), K‑M9 (ancestral to N, O, P, R; 43000 BC Ust'-Ishim man carried a descendant of this haplogroup: K2a), P‑M45 (ancestral to Q and R).
BMAC individuals were largely derived from local, Chalcolithic populations similar to those found in Geoksyur. A genome of a woman from 2800 BC - 2300 BC Rakhigarhi, Northern India (close to Punjab and New Delhi) matched the DNA from 11 other individuals who had been found at sites in Iran and Turkmenistan from similar period. A comparison of modern Indo-Iranian populations with the ancient genome has shown genetic continuity with the BMAC cluster, except for their high admixture with Steppe populations (Andronovo Culture), that occurred at the end of BMAC after 2000 BC. The first genetic outliers observed in several BMAC individuals may represent the very beginning of this demographic event. According to Narasimhan et al. 2019, Steppe pastoralist ancestry appeared in outlier individuals at BMAC sites by the turn of the second millennium BC around the same time as it appeared on the Southern Steppe (in Sintashta Culture and Andronovo Culture).
The Central Asian Steppe group, which admixed with BMAC does not harbour the Baikal Hunter-Gatherer genetic component because the BHG component did not arrive in the Central Asian Steppe until the late Iron Age. The best proxy for admixture with BMAC is the subpopulation formed by four individuals all belonging to the Kytmanovo site of Andronovo Culture (1446 BC - 1298 BC male from Kytmanovo already carried Y‑DNA R1a‑Z2124). These individuals have a very similar genetic profile to that of individuals from Sintashta, near the Caspian Sea. The screening of the individuals associated with the Andronovo horizon in the data shows that they formed a moderately heterogeneous group, with genetic proximities that do not necessarily correlate with geographical or cultural proximity. For example, Srubnaya-Alakulskaya individuals are more closely related to individuals grouped under the precise Andronovo label than Srubnaya from the Samara region.
According to a map shared by the Twitter user Nrken19, modern populations genetically (aDNA) closest to the 1971 BC Bronze Age male from Sappali Tepe, Uzbekistan (BMAC) are in following order:
- Balochi and Brahui from Pakistan;
- Tajiks from Tajikistan; Pashtun from Afghanistan; Kalash and Burusho from Pakistan; Mazandarani and Farsi from Iran; Kurds from Turkey, Syria, Iraq and Iran;
- Kashmiri and Khatri from Northern India; Turkmen from Turkmenistan; Azerbaijanis from Azerbaijan;
- Uzbeks from Uzbekistan; Uyghurs from Xinjiang; Bhumij from West Bengal, India; Turks from Central Turkey;
The 2200 BC - 1600 BC males from Sappali Tepe, Gonur, Bustan (Boʻston) and Sumbar, who carried the Y‑DNA haplogroup R2a still archaeologically belonged to the BMAC (Oxus Civilization). In the post-1200 BC Swat Valley, Pakistan males carrying R2a appear next to males, who carry the Sintashta derived R1a‑Z94 haplogroup (from R1a‑Z93). None of the Yamna/Afanasievo derived Y‑DNA R1b‑Z2103 appeared in the Swat Valley, even if some males from Sintashta still carried this Y‑DNA haplogroup (2012 BC sample I1020). North of Pakistan there are three additional ancient samples with detected Y‑DNA R1a‑Z93: one from 1497 BC Kokcha, Uzbekistan (sample I12499) and two from 1200 BC Kashkarchi, Uzbekistan. One of males from Kokcha, Uzbekistan from around 1738 BC carried Y‑DNA haplogroup Q1a1b1, which is related to both Native Americans and Siberian Kets and it is yet another sign of some Ancient North Eurasian derived genes in Central Asia.
A 1207 BC man from Katelai (Swat), Pakistan carried both Y‑DNA R2a3a2b2c and mtDNA U7b. Modern distribution of mtDNA haplogroup U7 almost perfectly matches the distribution of Y‑DNA haplogroup R2 shown on a map above (and below). This supports the hypothesis of a local origin of Y‑DNA R2a and R2b in the Swat Valley of Pakistan because the carriers of mtDNA U7 spread to South Asia and Europe before the suggested Bronze Age expansion of Indo-European languages from the Andronovo Culture and mtDNA U7 originated in the Near East and then spread towards South and Central Asia prior to the Holocene. However, low amounts of mtDNA U7 in West Bengal and Orisa most probably deny the appearance of mtDNA U7 together with Y-DNA R2a in South Asia (but not in Central Asia or Pakistan) and it is still more likely that Y-DNA R2a spread to East India together with Y‑DNA R1a‑Z93, which came from the Andronovo Culture and then those two Y‑DNA haplogroups spread together from the Swat Valley of Pakistan. The latter is also supported by the elevated amounts of mtDNA U7 in Gujarat and Rajasthan and much lower amounts of Y‑DNA R2a there.
Ancient individuals from the Swat Valley of Pakistan show that the Andronovo Culture (Central Asian Steppe) ancestry integrated further South around 1500 BC - 1200 BC and nowadays this genetic component makes up to 30% of ancestry in many South Asian populations. That Central Asian Steppe ancestry in South Asia has the same genetic profile as that of the Bronze Age Eastern Europe, tracking a movement of people, who affected both regions and likely spread the unique features shared between Indo-Iranian and Balto-Slavic languages.
R2b in Ancient Samples
- 4000 BC - Anau Tepe (Tepe-Anau), Turkmenistan - Y‑DNA R2b (R‑FGC50368), mtDNA W3a1 (sample I4087)
- 850 BC - Loebanr (Swat), Pakistan - Y‑DNA R2b (R‑FGC50368), mtDNA W3a1b (sample I8997)
- 850 BC - Loebanr (Swat), Pakistan - Y‑DNA R2b (R‑FGC50368), mtDNA W3a1b (sample I8998)
That's all. Those two males from Loebanr were most probably brothers from the same mother and again the oldest subclades of Y‑DNA R2 appear near the Swat Valley and in Central Asia instead of South India (or South Asia in general). The oldest sample of mtDNA W3a1 in Central Asia comes from that 4000 BC male from Anau Tepe, who also carried Y‑DNA haplogroup R2b just like those two brothers.
Second oldest sample carrying mtDNA W3a1 comes from a 2917 BC Yamna Culture woman from Prydnistryanske, Ukraine (very close to Moldova). Bronze Age samples of that mtDNA haplogroup come mostly from European and Central Asian cultures such as Corded Ware, Baden, Unetice, Trzciniec, BMAC (Sappali Tepe, Uzbekistan), Scythians from Kazakhstan. Its sister haplogroup W3a2 is nowadays found mostly in Tajikistan, England, France, Slovakia, Romania, Poland and Ukraine.
The 2022 paper by Guarino-Vignon et al. showed that the Neolithic and Chalcolithic samples from Central Asia, including those from Tepe-Anau genetically resemble modern Brahui, Balochi, Makrani, Kalash and Pathans (Pashtuns) but modern Yaghnobis and Tajiks are dramatically shifted from those samples towards Yamna and Iron Age Turkmenistan (Scythians, Kushans). Some samples from Early Middle Bronze Age Turan (circa 1500 BC) resemble those from Central Asian Steppe (Andronovo Culture) and those of modern Ossetians. The Burusho people appear closer to Pathans and Kalash but form their own cluster far away from the ancient Central Asian samples and Tajiks. The Burusho are still closest to the South Asian cluster.
Modern samples of R2b were only detected in Pakistan (Islamabad; Punjab; Azad Kashmir), India (Punjab), China (Shandong), Iraq (Al Anbar), Saudi Arabia (Hāʼil), Bahrain (Al Muharraq). It is possible that this haplogroup appeared in Saudi Arabia, Iraq and Bahrain already in the Neolithic but the Iron Age Persian expansion or some other recent events could also be responsible for spreading R2b to those regions. This can not be determined.
Below is a heatmap with visible percentages of Y‑DNA haplogroups R2a and R2b in Africa and Eurasia combined with a marked appearance of their ancient samples:
R2a in Kazakhstan and Europe
The relatively high amount (0% - 25%) of Y‑DNA R2a in the Kazakh Tore tribe, 12% in Zhanakorgan district, 6.3% - 10% in Kozha tribe, 5.4% in Jalayir tribe, 2% in Sirgeli and Alban tribes, 1% in Baiuly tribe could be explained by the backward migration of Scythians from the territory of BMAC and Southern Andronovo (there are no ancient samples of Y‑DNA R2a from the territory of Kazakhstan). Yaghnobis (cultural and genetic descendants of Scythians) show no genetic admixture from South Asia (unlike Tajiks), while both Yaghnobis and Tajiks show genetic affinity to BMAC and Andronovo. This backward Scythian migration through Kazakhstan is further proven by 8% of Y‑DNA R2a in Ossetians from Alagir, 7.9% in Balkars (descendants of Scythian Alans and Turkic tribes; they carry very high amounts of Central Asian Y‑DNA R1b‑M73 and Iranic Y-DNA R1a‑Z2124 from R1a‑Z94), 16% in Chechens, 20% in Kalmyk-Oirats from Derbet, Kalmykia and 1% in Eastern European countries.
During the 14th century CE, Alania was destroyed by Timur and many of the Alans, Cumans and Kipchaks migrated to Eastern Europe. This genetic influx might go back even further in time as R1a‑Z2124 was already detected in the ancient Hun (5th century CE), Avar and Hungarian conqueror (post-850 CE) samples from Hungary, a descendant of this Y‑DNA haplogroup, namely the R1a‑Z2123 is nowadays mostly prevelant in Bashkiria, Kazakhstan (in Tore, Kozha, Tarakty, Sirgeli, Oshakty, Kangly, Jalayir, Zhetiru and Kypshak tribes), Northern Afghanistan, Tajikistan, among Karachay-Balkars and it was the Y‑DNA haplogroup of the Hungarian Árpád Dynasty.
Even older sample with this Y‑DNA haplogroup is a 380 BC - 200 BC Scythian from a kurgan near Samara (I0247), who carried Y-DNA R1a1a1b2a2a (R1a‑Z2125) and mtDNA G2a4. Both Y‑DNA haplogroups R1a‑Z2124 and R1a‑Z2125 were present in the territory of the Middle Bronze Age Kazakhstan because a 1900 BC - 1300 BC male from Dali in Bayan-Zhurek mountains, Eastern Kazakhstan carried Y‑DNA R1a‑Z2124 and mtDNA U5a1a2a (sample I0507), this site is only 100 km away from Northern Xinjiang. Another male from 1600 BC - 1196 BC Taldysay, Ulytau region, Central Kazakhstan carried R1a‑Z2125 and mtDNA H3g (sample I4787).
The Kalmyk Dörwöds (Dörbet) in Mongolia are characterized by high frequencies of Y‑DNA haplogroups C3d‑M407 and R2a‑M124 (15.2%). It is noteworthy that the age of haplogroup R2aM1‑24 found in both Dörbet and Oirats from Kalmykia shows the best correspondence to the historical chronology of the Kalmyk dispersals. Haplogroup D-M174, albeit rarely found in the Dörwöds and Torguuds (about 2%), reveals genetic affinity to the Tibetan populations, where this haplogroup was present probably before the Last Glacial Age. Another rare Y‑DNA haplogroup N1a‑M128, which frequently occurred only among Kazakhs (8.1%) in Central Asia, was also detected in the Buzava Kalmyks, who live next to Derbet in Kalmykia and carry up to 17.4% of Y‑DNA haplogroup R2a.
Phylogenetic network of haplogroup R1a1a‑M17 (carried by 3.3% of Kalmyks) demonstrates that two haplotypes of the Kalmyks coincide with the haplotypes common among different populations of South Siberia (Tuvinians, Altaians and Sojots) and Central Asia (Tajiks and Pathans), two haplotypes with populations of Pathans, Persians and Indians, and one haplotype with South Siberians (Shors and Tuvinians).
A median network of R2a‑M124 haplotypes derived from 12 Y‑STR loci in the Kalmyks, Buryats (2.7% of R2a) and populations of Southwestern and South Asia (in which this haplogroup is present at a relatively high frequency) reveals common haplotypes observed in Kalmyks and Buryats, whereas there is no haplotype sharing between these and other comparative populations. However, the R2a‑M124 haplotypes found in the Kalmyks and Buryats are still the derivatives of Indian subclades of R2a. This suggests a recent common ancestry and/or expansion of the Kalmyk R2a‑M124 lineages from India or Southern Central Asia.
The descendants of Y‑DNA R2a‑F2791 subclade are nowadays found only in Latvia, Ukraine, Slovakia, Chechnya, Georgia, Kuwait, Saudi Arabia, India, Pakistan, Afghanistan and Iran. The R2a‑Y101424 subclade of R2a‑Y3399 (basal R2a‑M124) found among Kurds in Turkey is also present in Iraq, Pakistan, Lebanon, Uzbekistan and Saudi Arabia so it most probably was not mediated there by the Scythians. Kurmanji Kurds from Georgia carry around 44% of Y‑DNA R2a‑M124. The Y‑DNA haplogroup R2a has not been detected in the Roma population of Europe. They mostly carry: 44.8% of H‑M82, 22.6% of I‑M170, 12.7% of J2a‑M67, 6.7% of R1‑M173, 3.6% of E‑M36, 2% of J‑M92, 1.6% of C‑M217, 0.4% of R‑M17 (R1a1a) and aren't responsible for the appearance of Y‑DNA R2a in Europe (the Scythians are and from the 17th century CE the Kalmyks).
R2a in China

Archaeological excavations at the 2000 BC site of Sappali Tepe, located in the North Bactrian oasis of Southern Uzbekistan, during the 1960s and 1970s yielded the earliest evidence of silk outside of China and raised the possibility that the East‑West contacts along the Great Silk Road may be far older than previously thought.
People from the Southern Gansu province of China nowadays carry 3.4% of Y‑DNA haplogroup R2a. During the Bronze Age the Qijia Culture (2200 BC - 1600 BC) thrived in that region and it might one of the factors why the R2a haplogroup spread to Central China. Qijia Culture is distinguished by the presence of numerous domesticated horses (in evidence also genetically after DOM2 horse spread to China after ca. 2000 BC), practice of oracle divination, metal knives and recovered axes, which point to some interactions with Siberian and Central Asian cultures, in particular with the Seima-Turbino complex (Okunevo Culture). Archaeological evidence points to plausible early contact (often violent) between the Qijia Culture and Central Asia. In spite of all the archaeological evidence of its Western contacts, those most probably were only trade relations as all males from the 2000 BC Mogou site of the Qijia Culture carried only East Asian Y‑DNA haplogroups: O3a2 and O3a2c1a and did not show any genetic affinity towards West Eurasia. It means that Y-DNA haplogroup R2a appeared in Central China only later in history.
4% of R2a in Western Xinjiang and 2% in Eastern Xinjiang might point to its appearance in that region after 1500 BC - 1300 BC because a study from 2021 by Ning et al. proved that the appearance of European mtDNA in 1500 BC - 1300 BC Western Xinjiang is correlated with the appearance of Yamna (Steppe) and Andronovo related ancestry.
In the same study mtDNA samples from the Qijia Culture clustered with East Asian and South Asian samples far away from European samples, this again suggests that the speculated appearance of Y‑DNA haplogroup R2a in China during the Early Bronze Age either wasn't correlated with the appearance of Yamna or Andronovo related ancestry or did not happen during the Qijia period in Gansu. The Qijia mtDNA samples were not far away from the Late Bronze Age Kayue, China; Bronze Age Khovsgol, Mongolia and Neolithic samples from Baikal, Russia. Those three geographic regions nowadays harbour around 3% of R2a. Kayue Culture (900 BC - 600 BC) most probably developed from the Western part of the Qijia Culture. Early Bronze Age Tarim (Xinjiang) clustered with the Kayue Culture and Neolithic Baikal but not with the European samples.
The only Asian ancient mtDNA samples clustering close to those from Europe were: Eneolithic Turkmen (Namazga Culture), BMAC, MLBA Central Asian Steppe, Iron Age Shirenzigou and Northern Xinjiang Afanasievo (a proof that Tocharians and Yuezhi are the descendants of the Afanasievo Culture). After 1000 BC the stone based burial type spreads from Northern Xinjiang Dzungaria (Afanasievo mtDNA) to Eastern Xinjiang, this might represent the earlieast spread of Tocharian languages to Eastern Xinjiang noted by archaeology.
According to phenetic comparisons the Tarim Basin (Xinjiang area) experienced a significant gene flow from highland populations of the Pamirs and Fergana Valley (modern day Eastern Uzbekistan) after 1200 BC. These highland populations may include those who later became known as the Saka (Scythians) and who may have served as "middlemen" facilitating contacts between the East (China) and West (Bactria) along what later became known as the Great Silk Road. The ancient Scythian DOM2 horse belonged to exactly the same breed as that of Boz Adyr, Xiongnu (from Gol Mod 2 Cemetery, Mongolia) and Karasuk, all those breeds were also closely related to the DOM2 horse from Sintashta, meaning that the people responsible for spreading the final breed of DOM2 horse to China were the Scythians. This lineage of horses survived at least until the 8th century CE in Central Asia at Boz Adyr, Kyrgyzstan. Bronze Age Deer Stone horses from Mongolia, medieval Aukštaičiai horses from Lithuania (9th - 10th century CE), and Iron Age Pazyryk Scythian (6th century BC) horses showed similar diversity levels.
This might point to the earliest possible date of 1200 BC - 700 BC for the arrival of Y-DNA R2a in the Tarim Basin and points to a similar backward migration of Scythians to the territory of late Andronovo Culture, which also took place in Kazakhstan. The Saka (Scythian) presence has been found in various locations in the Tarim Basin, for example in the Keriya region at Yumulak Kum (Djoumboulak Koum, Yuansha) around 200 km East of Khotan, with a tomb dated to as early as the 7th century BC. Surviving documents from Khotan (300 BC - 1006 CE) of later centuries indicate that the people of Khotan spoke the Saka language (Khotanese), an Eastern Iranian language that was closely related to the Sogdian language from Central Asia. Additionally the mtDNA samples from Iron Age Western Xinjiang and Southern Xinjiang were shifted from the Bronze Age Xinjiang samples towards BMAC, Tian Shan Saka, Tagar (Scythians), Iron Age Sarmatian and Hungary Bronze Age.
According to the 2022 V. Kumar et al. study on ancient DNA from Xinjiang (201 samples), the Bronze Age (3000 BC - 1000 BC) Northern and Western Tarim Basin is mainly represented by Y-DNA haplogroups: R1b1 (majority), R1a2 (it is either very rare R1a‑YP4141 or R1a‑Z93), Q2a, Q2 and Q1b1. The Late Bronze Age in Western Tarim Basin (probably circa 1000 BC) yields the first appearance of Y‑DNA R1a1. It is during the Iron Age (1000 BC - 1 BC) when the majority of Y‑DNA haplogroups related to Central Asia appear in Western Tarim Basin: R1a1 (majority), R1b2 (R1b‑PH155), Q2a1, Q1b2, Q1b1, J2a1, J2a2, J2b2, J1a2, L1a2, E1b1 (E1b1b1 was already found at the 2011 BC Gonur site of BMAC so it is not Greek or Macedonian), I2a1 (European). The Iron Age Southern Tarim Basin is dominated by Y‑DNA: G2a2 (majority), R1a1, L1a1, Q1b1 (majority), Q1b, Q1, N1a1 and Iron Age Northern Tarim Basin by Y‑DNA: R1b1, R1a1 and R1a2.
It means that this study in opposition to 2021 Zhang et al. proves that the Tocharian languages (R1b1) were first in the Tarim Basin right next to some isolated unknown ANE languages (Q2a, Q1b) and exactly after 1000 BC the Scythian genetic influx occured in Western Xinjiang. The Y‑DNA haplogroup O2 appears in the Eastern Tarim Basin only during the Iron Age and in the Southern Tarim Basin much later in the historical era (1 CE - present).
Deeper classification of some of those detected Y-chromosomes on YFull showed that two Xinjiang individuals from 1451 BC - 1374 BC and 739 BC - 494 BC already carried the Y‑DNA haplogroup R1a‑Z93; two from 1571 BC - 1460 BC and 353 BC ‑ 7 BC carried the Iranic Y‑DNA R1a‑Z2123. The R1b‑FT292014 haplogroup from Xinjiang is nowadays found only in Pakistan, while R1a‑YP1548 from a 693 BC Xinjiang man is found only in Kazakhstan, Altai, Kyrgyzstan and Shandong, China (next to 6.7% of R2a in Jiangsu, China).
Surprisingly on aDNA PCA four Late Bronze Age and two Bronze Age Tarim Basin individuals were identical to modern Europeans. Remaining BA samples from Tarim Basin clustered with Early Bronze Age Dzungaria (Proto-Tocharians). Those people might literally be the ancestors of Tocharians and those 6 people "from Europe" were either European mercenaries/merchants or individuals, who still preserved their Yamna/Afanasievo gene pool (maybe they did not mix with the ANE derived locals). Samples of EMBA (1700 BC) Tarim Mummies from the 2021 Zhang et al. paper created their own cluster far away from the Afanasievo/European Tarim Basin population and appeared closer to the supposed ancestral ANE population. During the Iron Age the Tarim Basin samples shifted towards Iran Neolithic (BMAC) and East Asia but still did not move to the exact area of modern Uyghur, Iron Age Southern Tarim Basin and Iron Age Shirenzigou samples.
When it comes to Horpa (Qiangic) speaking population of Daofu, Western Sichuan, China, where R2a makes up 6.25% of all Y‑DNA, on PCA they appear to be closest genetically to Han-Xinjiang and Tibetan-Shigatse populations. The European mtDNA haplogroups were not found among Horpa (Qiangic) speaking populations. The mtDNA (maternal) variation of Qiangic populations was also largely contributed by Northern Asian prevalent haplogroups, including haplogroups A, C, D, and G. In addition, cultural features of the upper Yellow River basin, such as painted pottery, millet agriculture, and urn burial, are prevalent in the Neolithic sites of Western Sichuan, probably due to the demic diffusion via the genetic corridor.
Hui from Ningxia (close to Gansu and Henan) carry 3.2% of R2a, they also carry 1.6% of R1b1b2 (R1b‑M269) and 3.2% of R1a1, unlike Man from Liaoning, who carry 1.5% of R2a but none of the Y-DNA R1 dervied haplogroups (just like Qiang from Sichuan and Han from Gansu who carry only R2a). Han from Jiangsu also carry 8.9% of R1a1 next to 6.7% of R2a. In general R1a and R1b is not totally absent in China as Hui from Yunnan carry 10% of R1b1c and 10% of R1a (next to 10% of J1, 10% of Q1a3 and 0% of R2a). Chinese from the Henan province (next to Gansu) also carry around 1.6% of R1b‑M269
R1b1b1 (R1b‑M73 brotherly to R1b‑M269) has also been detected in 8.3% of Chinese Mongolian, in 25% of Kyrgyz from Xinjiang and in 6% of Uyghurs from Xinjiang (they also carry 30% of R1a1, 16% of J2a and 4% of R2a). R1b‑M73 was detected mainly in NEAS (Kumandins, Mongolians, Chinese, Bashkirs, Northern Pakistani and Pamiri) and was sporadically detected in South Asia and West Eurasia (except for Karachay-Balkars and Kalmyks). It is possible that this haplogroup together with R2a and R1a‑Z93 spread to those regions with migrations of the Saka after 1000 BC - 700 BC and later with those of Xiongnu, Wusun, Yuezhi (probably to Gansu) or Kushans after the 3rd century BC.
In general the star-like structure of Y‑DNA R2a‑M124, which includes the Chinese samples suggests that it reflects a relatively recent expansion from South or Central Asia to North-East Asia via the Northern route and more diversified R2 haplotypes occur in the areas around Pakistan and India instead of North-East Asia.
R2a in Thailand and Malaysia
The Mon from Northern Thailand show the presence of haplogroups usually found in South, Central and West Asia: 16.7% of R‑P249 (R2‑M124) and 5.6% of J‑M172 (J2). Connection between the ethnic Mon and populations from South and Central Asia was already proposed from previous identification of mtDNA lineage W3a1b. Both groups of the Mon-Khmer speaking Lawa groups showed high differences between each other and from other populations, presenting low levels of haplogroup diversity with high frequencies of O‑PK4 (O1b1a1) (72% in Lawa 1) and N‑M231 (56% in Lawa 2).
The native language of Mon is Mon, it belongs to the Monic branch of the Mon-Khmer language family and shares a common origin with the Nyah Kur language, which is spoken by the people of the same name and who live in the Northeastern Thailand.
The groups from Thailand, where Y‑DNA haplogroup R1a has been detected are: Khon Muang 6 (9% of R1a; 4.6% of J2; 0% of R2a), Yuan 1 (5.3% of R1a; 0% of J2; 0% of R2a), Yuan 3 (4.2% of R1a; 0% of J2; 0% of R2a). It means that the appearance of R2a in Thailand could have been accompanied by the spread of Y‑DNA haplogroups R1a (usually R1a‑Z94 derived R1a1a1b2a1b: R1a‑Z2124) and J2.
Y‑DNA R2a (R‑L266, same as R‑M124) and mtDNA R21 has been detected in one modern male (JEH002) from the Malaysian Jehai tribe, who live next to the Thailand's Southern border. Other male (JEH04) from the same tribe carried Y‑DNA R1a1a1b2a R1a‑Z94 and mtDNA M13b1.
If the appearance of Y‑DNA R2a correlates with that of R1a‑Z94 in Thailand and Malaysia, then the spread of R2a in Thailand could occur only after 1200 BC (after R1a‑Z93 associated Painted Grey Ware Culture appeared in Central India next to West Bengal) but this can not be determined yet. Ancient DNA samples from Thailand carrying Y‑DNA R2a could undermine this statement but just like in the case of ancient samples from Southern India, there aren't any carrying Y‑DNA R2a.
R2a in Sri Lanka and Maldives

According to the Mahāvamsa, a Pāḷi chronicle written in the 5th century CE, the original inhabitants of Sri Lanka are said to be the Yakshas and Nagas. Sinhalese history traditionally starts in 543 BC with the arrival of Prince Vijaya, a semi-legendary prince who sailed with 700 followers to Sri Lanka, after being expelled from Vanga Kingdom (nowadays Bengal). He established the Kingdom of Tambapanni, near modern Mannar.
Vijaya (Singha) is the first of the approximately 189 monarchs of Sri Lanka described in chronicles such as the Dipavamsa, Mahāvaṃsa, Cūḷavaṃsa, and Rājāvaliya. Once Prakrit speakers had attained dominance on the island, the Mahavamsa further recounts the later migration of royal brides and service castes from the Tamil Pandya Kingdom to the Anuradhapura Kingdom in the early historic period. Excavation at Anuradhapura in Sri Lanka has unearthed Painted Grey Ware pottery from the "Basal early historic" period of Anuradhapura (600 BC - 500 BC) showing connections with North India.
D1S80 allele frequency is similar between the Sinhalese and Bengalis, suggesting the two groups are closely related. The Sinhalese also have similar frequencies of the allele MTHFR 677T (13%) to West Bengalis (17%). A study from 2007 found similar frequencies of the allele HLA‑A*02 in Sinhalese (7.4%) and North Indian subjects (6.7%). HLA‑A*02 is a rare allele which has a relatively high frequency in North Indian populations and is considered to be a novel allele among the North Indian population. This suggests possible North Indian origin of the Sinhalese.
With both the Sri Lankan Tamils and Sinhalese in the island sharing a common gene pool of 55% they are farthest from the indigenous Veddahs. This is also supported by a genetic distance study, which showed low differences in genetic distance between Tamils and the Sinhalese.
Groups ancestral to the modern Veddas were probably the earliest inhabitants of Sri Lanka. Their arrival is dated tentatively to about 40000 - 35000 years ago. They show a relationship with other South Asian and Sri Lankan populations, but are genetically distinguishable from the other peoples of Sri Lanka, and show a high degree of intra-group diversity.
Parental admixture analysis for mtDNA and Y-haplogroup data indicates a strong genetic link between the Maldive Islands and mainland South Asia, and excludes significant gene flow from Southeast Asia. Paternal admixture from West Asia is detected, but cannot be distinguished from admixture from South Asia. Maternal admixture from West Asia is excluded. Within the Maldives there is a subtle genetic substructure in all marker systems that is not directly related to geographic distance or linguistic dialect.
Language studies and historical records point to a historical relationship of the Maldivian language, Dhivehi, with the Sinhalese language of Sri Lanka, making it the Southernmost Indo-European language at the time the Maldives were populated. Maldivian and Sinhalese are descended from the Elu Prakrit of ancient and medieval Sri Lanka.
The distribution pattern of mtDNA and Y‑DNA haplogroups in Maldives resembles that of India the most. The most prevalent Y‑DNA haplogroups in Maldives are F*(xG,H,I,J,K) (6.7%), H‑M69 (17.7%), J2 (18.4%), L‑M20 (15.6%), R1a1a (21%) and R2a (15 in 141 samples: 10.6%), which combined correspond to 90% of the individuals.
The above genetic evidence and historical stories are supported by the distribution of Y‑NA R2a in India, Nepal, Sri Lanka and Maldives beginning with 3% - 40% in Uttarakhand (6% in Goswami, 10% in Brahmins and 40% in Shah), 20% in New Dehli, then R2a reaches the highest amount of 83% in Jaunpur (Northern India), 5% in Chitwan district of Nepal and 10% - 25% in Kathmandu, 25% - 50% in West Bengal (Karmalis from West Bengal carry 100% of Y‑DNA R2a), then when going along the Eastern coast of India R2a drops to 14% in Eastern Odisha and reaches 73% in Kamma Chaudhary population near Guntur, then it finally reaches 38% in Sri Lankan Sinhalese and from there 10.6% in Maldives.
The amounts of 10% - 14% in South Indian Dravidian speaking populations of Tamils and Telugu also support this path of Y‑DNA R2a dispersal in India. Y‑DNA R2a started spreading by the Western coast of India and reached 20% in Konkan but then it formed an isolated sphere surrounded by 3% in Gujarat state, 2% in Madhya Pradesh state, 5% in Kannada tribes and 10% in Tamil tribes. Konkani and Marathi are also linguistically closer (than Bengali) to Dhivehi and Sinhalese and those four languages form the Maharashtri branch.
Languages and Genetics

Modern distribution of Y‑DNA haplogroups R2a and R2b covers the areas of not only the Indo-European languages but also: Dravidian Brahui in Pakistan; isolate Burushaski in Hunza, Pakistan; Horpa (Qiangic) near Xinlong, Western Sichuan, China; Monguor in Gansu, China; Mandarin in Jiangsu, China; Mon in Thailand; Arabic in Jordan, Kuwait and United Arab Emirates; Jehai (Mon-Khmer) in Malaysia; Kalmyk-Oirat, Buryat (Mongolic), Karachay-Balkar, Ossetian and Chechen in Russia; Kazakh in Kazakhstan; Oirat in Western Mongolia; Lodha, Kannada, Kerala, Malayalam, Tamil, Telugu and Sora in India.
When it comes to Indo-European languages the distribution of Y‑DNA R2 covers the areas of: Tajik, Bartangi and Wakhi (Pamir languages) in Tajikistan; Nuristani, Pashai, Hazara and Aimak in Afghanistan; Balochi, Pashto, Urdu and Punjabi in Pakistan; Persian and Balochi in Iran; Kurdish in Turkey, Iraq, Iran; Kurmanji in Georgia; Dhivehi in Maldives; Sinhalese in Sri Lanka; Kashmiri, Hindi, Bhojpuri, Bengali, Odia, Punjabi, Marwari, Marathi (in Konkan) and Konkani languages in India. All those languages belong to the the Indo-Iranian branch of the Indo-European languages.
R2a is only weakly related to the broad distribution of the Hindi language and in areas of Dravidian languages its amounts reach from 3% to 10%. Even if this Y‑DNA haplogroup predates the Yamna (steppe) related genetic input in Central Asia it can not be associated with the appearance of Indo-European languages in Western North India, especially in Gujarat, Rajasthan and Madhya Pradesh.
Languages mentioned above from the areas where R2a exceeds 14% are marked in bold. From those the ones closest geographically to the appearance of Y‑DNA R2 in ancient samples are: Pamir, Punjabi, Burushaski and Nuristani languages. Václav Blažek in his 2019 paper "Toward the question of Yeniseian homeland in perspective of toponymy" suggests that the Pamir languages have a Burushaski-like substratum. Although Burushaski is today spoken in Pakistan to the South of the Pamir language area, Burushaski formerly had a much wider geographic distribution before being assimilated by Indo-Iranian languages.
In 203 Burushaski words I found only 15 (that is 7.4%), which might be related to the Indo-European languages: pʰu ("fire"), sua ("good"), ga'rurum ("hot"), mi ("we"), ja ("I"), te ("that"), hir ("man"; Latin: vir), mosh ("nose"), ren ("hand"), girashom ("play"; Old Church Slavonic: igrati; Lower Sorbian: graś), jee ("live"), sa ("sun"), thas ("smoke"), tik ("earth"; Hittite: tekan; Tocharian A: tkaṃ). Similar amount of words in common appears between the Indo-European and Native American languages associated with Y‑DNA haplogroup Q (brother of R* from ANE; 5/96 in the words section of my website resulting in only 5.2% of shared vocabulary).
It means that the Burushaski language is still a valid candidate for the language most likely associated with the Y‑DNA haplogroup R2. Other most common Y‑DNA haplogroup among Burusho is R1a1 (26%) and from those 15 "Indo-European" Burushaski words only 4 are not in common with Sanskrit. Burushaski words not shared with Sanskrit but instead shared only with the European IE languages are marked in italic bold, and they make up 2% of vocabulary shared between the Y‑DNA R1b‑M269/R1a‑Z283 associated languages and Y‑DNA R2a "associated" Burushaski.
Other most frequent Y‑DNA haplogroups among Burusho are: 12.4% of L‑M357, 4% of L‑M20, 7.2% of J2‑M172, 4% of H, 2% of Q‑M242 (from ANE). Y‑DNA haplogroup L reaching 16.4% among Burusho is the second most likely candidate to be associated with the origin of the Burushaski language.
There are also some words in common between Indo-European (R1a and R1b), Horpa (6.25% of R2a) and Khroskyabs / Tangut (from the same language family branch as Horpa), which could possibly go back to the times of the basal R* haplogroup (ANE):
- Horpa (Rgyalrongic): zjar ("heart")
- Khroskyabs (Rgyalrongic): sjar
- Swedish: hjärta
- Bulgarian: сърце (sǎrce)
- Udmurt: сюлэм (sjulem)
- Horpa (Rgyalrongic): rɛku ("elbow")
- Lithuanian: ranka ("hand, arm")
- Latvian: roka ("hand, arm")
- Polish: ręka ("hand, arm")
- Burushaski: ren ("hand")
- Serbo-Croatian: ruka ("hand, arm")
- Quechua (Y-DNA Q): ruk'ana ("finger")
- Khroskyabs (Rgyalrongic): stî ("to exist")
- Hittite: asanta-
- Sanskrit: अस्ति (asti)
- Tangut (Rgyalrongic): khu ("dog")
- Tocharian A: ku
- Ancient Greek: κύων (kúōn)
- Old Irish: cú
- Hittite: kuwaš
Again, those similarities do not exceed 2% of shared vocabulary. The languages, which would exceed this barrier are the Indo-Iranian languages but the sole association of those language with only the Y‑DNA haplogroup R2 would result in the rejection of their association with Y‑DNA haplogroup R1a‑Z93. R1a‑Z93 is the only haplogroup, which strongly binds the Indo-Iranian languages with Europe. To say that Sanskrit originated already with haplogroup's R2 split from R* (circa 14000 BC) requires an explanation why the Y‑DNA haplogroup R2a is not as common as R1a‑M780 (from R1a‑Z93 but not from R1a‑Z94 or R1a‑Z2125) in Western North India. The Indo-European areas of India with 0% of R2a are Rajasthan and Assam, while in the Punjab disctrict without the Brahmins it reaches only 4%.
People from Malana in Himachal Pradesh, India speak the Sino-Tibetan Kanashi language and do not carry any Y‑DNA R2a at all but instead they carry: 60% of J2a1h, 27% of R1a, 10% of H and 3% of L. This high amount of R1a can not be ignored as "the Kanshi seems to be a mixture of Sanskrit and several Tibetan dialects".
It is important to notice that the distribution pattern of R1a‑Z93 derived haplogroups in South Asia (India, Nepal, Sri Lanka, Maldives) usually matches the distribution pattern of R2a‑M124, for example in Sri Lanka the amounts of R2a and R1a are almost equal, in Uttarakhand the Tharu carry 22% of R1a and 13% of R2a, the Goswami carry 6.5% of R1a and 6.5% of R2a, in Uttar Pradesh there is 19% of R2a and 26.5% of R1a1a. There are some exceptions tough like in Maldives where R1a is more frequent than R2a and in Gujarat where R2a is only 3% - 18% and R1a makes up the majority of Y‑DNA haplogroups there (from 10% to 60% depending on place of measurement), the Brahmins from Uttarakhand carry 46% of R1a and 11% of R2a.
To say that Iranian languages have nothing to do with R1a‑Z2125 (from R1a‑Z94 and R1a‑Z93) is to ignore the levels of that Y‑DNA haplogroup reaching more than 50% in Tajikistan, Kyrgyzstan (former Saka territory) and Northern Afghanistan (62% of R1a1a, 0.5% of R1b‑L23 and 11% of R2a). The only areas with lower frequencies of R1a‑Z93 are those with higher frequencies of R2a, so there is still some possibility that the Indo-European Nuristani or Pamir languages could have some association with the Y‑DNA haplogroup R2a but this is only a speculation (maybe better explained by their Burushaski substratum). The area of Dardic languages during the Bronze Age (1200 BC - 500 BC) in the Swat Valley of Pakistan contained more samples of Y‑DNA haplogroup R2a than what can be found in the people who live in this area today, namely the Kho (speakers of Khowar), Pathan (nowadays 0% of R2a; 50% of R1a) and Kalash (nowadays 0% of R2a; 20.5% of R1a). The aforementioned people from the Swat Valley fit into their own genetically (aDNA) isolated cluster, while the Burusho are close to Kho and Kalash but still form a slightly different cluster. This might be easily explained by much higher amounts of Andronovo derived ancestry in Kho and Kalash.

A study from 2015 by Ayub et al. showed that the Kalash people are genetically isolated from the South Asian populations and mostly resemble the Ancient North Eurasian Mal'ta Buret Boy (Paleolithic Siberian Hunter-Gatherers). It means that the ancestors of the Kalash arrived in the territory of Northern Pakistan already around 10000 BC - 8600 BC. Those ancestors most probably carried the Y‑DNA haplogroups R2 and Q. This does not mean that they did not receive any genetic input after 8600 BC. Kalash are even more genetically isolated than the Burusho people but still speak an Indo-Iranian language and carry 20.5% of R1a and 6.8% of R*. According to a 2016 study by Lazaridis et al. the Kalash from Pakistan are inferred to have around 50% of Yamna related ancestry, with the rest being Iranian Neolithic, Onge and Han. The Kalash have a high proportion of Y‑DNA haplogroup L3a lineages, which are characterized by having the derived allele for the PK3 Y‑SNP and are not found elsewhere. They also have predominantly Western Eurasian mitochondrial lineages and no genetic affiliation with East Asians.
The Khowar language (and with it other Dardic languages, including Chitral Kalasha) can surely be excluded from the proposed cultural descendants of Y‑NA haplogroup R2a because even if it is geographically close to the Burusho, who carry 14.4% of R2a, the Kho and Kalash carry none and the Khowar language still retains many words in forms closest to Sanskrit. The Western Eurasian mtDNA haplogroups (HV8, H19, H57, H24, C and, C4a) were predominantly observed in the Kho samples with overall frequency of 50%.
On aDNA PCA the Kho people are slightly shifted from Burusho and Kalash towards Iranian, Central Asian, Siberian and European samples. That is why "Kho can trace a large proportion of their ancestry to the population who migrated South from the Southern Siberian steppes (Andronovo Culture) during the second millennium BC (~110 generations ago). An additional wave of gene flow from a population carrying East Asian ancestry was also identified in the Kho (also in Balti and Burusho) that occurred ~60 generations ago and may possibly be linked to the expansion of the Tibetan Empire during 7th - 9th century CE". The Kho possess genetic ancestry components associated with the Yamna Culture and European Neolithic Farmers (Anatolia Neolithic + WHG); these three components taken together are characteristic of Middle Bronze Age populations from the Andronovo Culture, while the Early Bronze Age Central Asian Steppe populations lack the additional Anatolian Neolithic and WHG components. The shift of Kho from the 3500 BC Geoksyur, Turkmenistan samples is also evident.
The only remaining Indo-European candidates closest to the archaeological sites, where oldest R2a samples were found, would then be the Nuristani languages (some Nuristani males still carry Y‑DNA R2a). To prove that the Nuristani languages in Afghanistan are the descendants of a language spoken by the people who carried the R2a haplogroup in Central Asia during the Neolithic, one would have to compare how many words the Kamkata-viri language (maybe Kamviri dialect) does not share with Sanskrit, Avestan and European languages.
If this amount would be much higher than what Sanskrit does not share with Avestan and European languages then those "not shared" words most likely originated in the R2a associated substrum language, for example words similar to Sanskrit "मत्स्य (matsya)" ("fish") and Nuristani Kamviri "oa mâći" ("fish"). In general there are around 55 non-Indo-European words shared between Sanskrit and Avestan, which might have originated in the language related to the Oxus Civilization. Those 55 words and only 12% of R2a in that region (5% - 10% among other Dravidians in India) disqualify the Dravidian Brahui language as a descendant of a language spoken in the Oxus Civilization.
The ancient Y-DNA R2a samples predating 1500 BC come mostly from the territory of Turkmenistan and Uzbekistan, so one might suggest that they were related to the Iranic languages (spoken before the arrival of Turkmen and Uzbek languages). This might explain all the differences between Sanskrit and Avestan but the language of 3500 BC Turkmenistan and even that of BMAC remains unknown and in this supposed thesis, the Y‑DNA haplogroup R1a‑Z93 and Sintshta aDNA would be associated with Sanskrit but not with Avestan. Why would then the supposed "R2a associated Iranic languages" be much closer to R1a‑Z93 associated Sanskrit than Sanskrit would be to R1b associated Latin... I have no idea. One would have to prove that Sanskrit is closer to Latin than it is to Avestan or to Nuristani languages.
To conclude all the speculations... It is not possible to precisely identify a modern language, which would be closest to a language spoken by the people who after 10000 BC brought the Y‑DNA haplogroup R2* to Central Asia. This mystery might be solved in the future with a discovery of a language spoken by the Oxus Civilization or the Namazga Culture.
Summary
Y‑DNA haplogroup R2* originated in close proximity to Southern Central Asia in the territory of what is modern day Turkmenistan, Southern Uzbekistan, Tajikistan, Afghanistan, Northern Pakistan and Eastern Iran. There is no evidence supporting the South Asian origins of this Y-DNA haplogroup. People, who were the first carriers of Y‑DNA haplogroups R2a and R2b, in their aDNA mostly resembled the populations of Neolithic Iran (Zagrosians), Neolithic Anatolia and to a lesser extent the Ancient North Eurasians. Another proof of those genetic components in people from the Neolithic and Chalcolithic archaeological sites of Central Asia is the appearance of Y‑DNA haplogroups: J1a, J2a, R2a, R2b, Q1a and P1 in their genome. The Ancient North Eurasian genetic component is shared between the earliest individuals carrying Y‑DNA haplogroup R2b from the 4000 BC Anau Culture, Y‑DNA R2a from the Oxus Civilization and Y‑DNA R1a1 carrying Tarim Mummies from the 1700 BC Xiaohe Cemetery in Eastern Xinjiang.
The earliest inhabitants of the Early Bronze Age Xinjiang (2200 BC - 1700 BC Tarim Basin) were the descendants of the Afanasievo Culture in Northern and Western Tarim Basin and an unknown isolated ANE related population in Southern Tarim Basin. Those two populations lived separately and both did not carry the Y‑DNA haplogroup R2. Haplogroups such as Q2a and Q1b might be related to that isolated ANE related population and Y‑DNA haplogroups R1b‑PH155, R1b1 (probably R1b‑Z2103) and R1a1 to the Proto-Tocharian (Afanasievo related) population of the Early Bronze Tarim Basin. The earliest possible influx of the Indo-Iranian languages into Western Tarim Basin occurred in the years 1571 BC - 1460 BC and 1451 BC - 1374 BC when two males carrying Y-DNA haplogroups R1a‑Z93 and R1a‑Z2125 appeared there for the first time.
After 1200 BC - 700 BC the differences between Western Xinjiang (nowadays 4% of R2a) and Eastern Xinjiang (nowadays 2% of R2a) begin to appear in the ancient DNA samples from those regions. Western Xinjiang became the destination for the Saka (Scythian) expansion (represented by the 1000 BC Cherchen Man, Yumulak Kum mummies from 650 BC Western Xinjiang and 350 BC Witches of Subeshi from Kucha) and this expansion is further proven by the usage of the Scythian Khotanese language in that region spanning the years 100 BC - 1006 CE.
Eastern Xinjiang during the Iron Age harbours the mtDNA haplogroups, which resemble those found in the Early Bronze Age Afanasievo Culture, however the Proto-Tocharian language was already in use in that region since the Early Bronze Age and this simply shows an additional influx of Afanasievo related genes from Dzungaria, Northern Xinjiang to Eastern Xinjiang. People, who carried Y‑DNA R2a most probably appeared in Central China and Tarim Basin during the Late Bronze Age or Early Iron Age but this hypothesis has to be strengthened with more ancient DNA samples from those regions. Other possible timeline for the Y‑DNA R2a dispersal in China is its association with the migrations of the Wusun, Xiongnu and the Yuezhi after the 3rd century BC and later the introduction of Buddhism to China by the Kushans.
The appearance of Y‑DNA R2a after the Early Bronze Age period outside Central Asia is correlated with the appearance of Y‑DNA R1a‑Z94 derived haplogroups, especially R1a‑Z2123, R1a‑Z2124 and R1a‑Z2125 but also with the appearance of the Y‑DNA haplogroup R1b‑M73. This is further proven by the common detected Andronovo related genetic influx (of mtDNA and aDNA) in those regions like in the post‑1500 BC Tarim Basin (Western Xinjiang). R2a, R1a‑Z93, R1b‑M269 and R1b‑M73 haplogroups often appear together in modern day China, Kazakhstan, Ossetia, Kalmykia, Mongolia and Kabardino-Balkaria, while in Thailand, Malaysia, Sri Lanka, Maldives and India Y-DNA haplogroup R2a appears together only with R1a‑Z93.
The most likely explanation for this phenomenon in China, Western Mongolia, Kazakhstan and Northern Caucasus (Alania and Sarmatia) is the expansion of the Scythians (Saka) and later in history other nomadic tribes (mostly Turkic, Hunnic and Mongolic in Eastern Europe or in China the Wusun, Xiongnu, Yuezhi and the Kushans). The additional vector of Y‑DNA R2a dispersal into Eastern Europe was the migration of the Kalmyk-Oriats from Western Mongolia in the 17th century CE.
From the Swat Valley of Pakistan the Y‑DNA haplogroup R2a spread together with R1a‑Z93 to India and the earliest possible date of that event spans the years 1500 BC - 1200 BC. The year 543 BC marks the expansion of those haplogroups in Sri Lanka and from there those haplogroups spread to Maldives. The expansion of those haplogroups in Thailand, Malaysia and Indonesia occurred sometime between those years or coincided with some later events (for example, with the expansion of Buddhism in Thailand after 400 CE), it can not be determined yet as there are not enough ancient DNA samples from those regions.
The timeline of the appearance of Y‑DNA R2a and R2b in Saudi Arabia and Kuwait can not be surely determined either. It might have coincided with the Persian expansion or occurred due to common contacts between Central Asia and Fertile Crescent since the Neolithic. Both the Neolithic contact and the Persian expansion is supported by the same R2a subclades shared only between Kurds, Arabs, Pakistanis and Iranians but not with China, Europe, Kazakhstan, Mongolia, Southern India, Sri Lanka and Thailand.
The original language of populations and cultures, where the first ancient DNA samples containing Y‑DNA haplogroups R2a and R2b were found can not be determined but the most likely candidates for a language descendant from those cultures are: Burushaski, Elamite, Bartangi, Wakhi or the Nuristani languages.
Genetic Studies
- E. Khussainova, I. Kisselev, O. Iksan et al. "Genetic Relationship Among the Kazakh People Based on Y-STR Markers Reveals Evidence of Genetic Variation Among Tribes and Zhuz": 2022
- F. Aghakhanian, B.-P. Hoh, C.-W. Yew, V. K. Subbiah, Y. Xue et al. "Sequence analyses of Malaysian Indigenous communities reveal historical admixture between Hoabinhian hunter-gatherers and Neolithic farmers": 2022
- Y-DNA R2a1 in one modern Wakhi and two Dushanbe Tajiks from: S. S. Dai, X. Sulaiman, J. Isakova, W. F. Xu "The Genetic Echo of the Tarim Mummies in Modern Central Asians": 2022
- T. Naidoo, J. Xu, M. Vincente et al. "Y-Chromosome Variation in Southern African Khoe-San Populations Based on Whole-Genome Sequences": 2020
- N. Balinova, H. Post, A. Kushniarevich, R. Flores et al. "Y-chromosomal analysis of clan structure of Kalmyks, the only European Mongol people, and their relationship to Oirat-Mongols of Inner Asia": 2019
- A. R. Isukapatla, M. Sinha, V. Pulamagatta et al. "Genetic Architecture of Southeast-coastal Indian tribal populations: A Y-chromosomal phylogenetic analysis": 2019
- V. M. Narasimhan, N. Patterson, P. Moorjani et al. "The formation of human populations in South and Central Asia": 2019
- NevGen Predictor "Comparative overview of distribution of Y-DNA haplogroups in Europe": 2019
- L. Damba, E. V. Balanovskaya, M. Zhabagin et al. "Estimating the impact of the Mongol expansion upon the gene pool of Tuvans": 2018
- A. Brunelli, S. Ghirotto et al. "Y chromosomal evidence on the origin of northern Thai people": 2017
- M. Zhabagin, E. Balanovska et al. "The Connection of the Genetic, Cultural and Geographic Landscapes of Transoxiana": 2017
- A. Bergström, N. Nagle, Y. Chen, S. McCarthy et al. "Deep Roots for Aboriginal Australian Y Chromosomes": 2016
- M. S. Jota, D. R. Lacerda, J. S. Sandoval et al. "New native South American Y chromosome lineages": 2016
- N. Negi, R. Tamang, V. Pande, A. Sharma et al. "The paternal ancestry of Uttarakhand does not imitate the classical caste system of India": 2015
- S. Bhandari, X. Zhang, C. Cui et al. "Genetic evidence of a recent Tibetan ancestry to Sherpas in the Himalayan region": 2015
- J. A. Trejaut, E. S. Poloni, Ju-Chen Yen et al. "Taiwan Y-chromosomal DNA variation and its relationship with Island Southeast Asia": 2014
- Chuan-Chao Wang, Lingxiang Wang et al. "Genetic Structure of Qiangic Populations Residing in the Western Sichuan Corridor": 2014
- 8211 BC Ganj Dareh, Iran sample from: E. Fernández, A. Pérez-Pérez, C. Gamba, E. Prats et al. "Ancient DNA Analysis of 8000 B.C. Near Eastern Farmers Supports an Early Neolithic Pioneer Maritime Colonization of Mainland Europe through Cyprus and the Aegean Islands": 2014
- B. Malyarchuk, M. Derenko, G. Denisova, S. Khoyt, M. Woźniak, T. Grzybowski & Ilya Zakharov "Y-chromosome diversity in the Kalmyks at the ethnical and tribal levels": 2013
- T. Yamamoto, T. Senda, D. Horiba et al. "Y-chromosome lineage in five regional Mongolian populations": 2013
- J. Pijpe, A. Voogt, M. Oven et al. "Indian Ocean Crossroads: Human Genetic Origin and Population Structure in the Maldives": 2013
- H. Lacau, T. Gayden, M. Regueiro, S. Chennakrishnaiah et al. "Afghanistan from a Y-chromosome perspective": 2012
- 2.7% of R2a among Buryats from: B. Malyarchuk, M. Derenko, G. Denisova et al. "Ancient links between Siberians and Native Americans revealed by subtyping the Y chromosome haplogroup Q1a": 2011
- H. Zhong, H. Shi, X-B. Qi et al. "Extended Y chromosome investigation suggests postglacial migrations of modern humans into East Asia via the northern route": 2011
- Wei-Hua Shou, En-Fa Qiao, Chuan-Yu Wei et al. "Y-chromosome distributions among populations in Northwest China identify significant contribution from Central Asian pastoralists and lesser influence of western Eurasians": 2010
- T. Mohammad, Y. Xue, M. Evison & C. Tyler-Smith "Genetic structure of nomadic Bedouin from Kuwait": 2009
- S. Fornarino, M. Pala, V. Battaglia, R. Maranta et al. "Mitochondrial and Y-chromosome diversity of the Tharus (Nepal): a reservoir of genetic variation": 2009
- K. K. Abu-Amero, A. Hellani, A. M. González, J. M. Larruga et al. "Saudi Arabian Y-Chromosome diversity and its relationship with nearby regions": 2009
- L. Caciagli, K. Bulayeva, O. Bulayev et al. "The key role of patrilineal inheritance in shaping the genetic variation of Dagestan highlanders": 2009
- Tamil DNA from: W. S. Watkins, R. Thara, B. J. Mowry, Y. Zhang et al. "Genetic variation in South Indian castes: evidence from Y-chromosome, mitochondrial, and autosomal polymorphisms": 2008
- V. Battaglia, S. Fornarino, N. Al-Zahery et al. "Y-chromosomal evidence of the cultural diffusion of agriculture in southeast Europe": 2008
- R. Trivedi, S. Sahoo et al. "Genetic Imprints of Pleistocene Origin of Indian Populations: A Comprehensive Phylogeographic Sketch of Indian Y-Chromosomes": 2008
- T. Gayden, A. M. Cadenas et al. "The Himalayas as a Directional Barrier to Gene Flow": 2007
- S. Firasat, S. Khaliq, A. Mohyuddin et al. "Y-chromosomal evidence for a limited Greek contribution to the Pathan population of Pakistan": 2007
- I. Nasidze, E. Y. Ling, D. Quinque et al. "Mitochondrial DNA and Y-chromosome variation in the Caucasus": 2004
- T. Kivisild, S. Rootsi, M. Metspalu et al. "The Genetic Heritage of the Earliest Settlers Persists Both in Indian Tribal and Caste Populations": 2003
- R. Qamar, Q. Ayub, A. Mohyuddin, A. Helgason et al. "Y-Chromosomal DNA Variation in Pakistan": 2002
References
Article and maps created between the 7th of December 2022 and 22nd of December 2022.
First published on the 22nd of December 2022.